Regular Expressions учебник
Начало работы с регулярными выражениями
Поиск…
замечания
Для многих программистов регулярное выражение - это своего рода волшебный меч, который они бросают, чтобы решить любую ситуацию синтаксического анализа текста. Но этот инструмент не волшебный, и хотя он отлично подходит к тому, что он делает, он не является полнофункциональным языком программирования ( т. Е. Он не является Turing-полным).
Что означает «регулярное выражение»?
Регулярные выражения выражают язык, определяемый регулярной грамматикой, которая может быть решена недетерминированным конечным автоматом (NFA), где согласование представлено состояниями.
Регулярная грамматика - самая простая грамматика, выраженная Иерархией Хомского .

Проще говоря, регулярный язык визуально выражается тем, что может выразить NFA, и вот очень простой пример NFA:
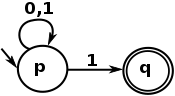
Язык регулярных выражений является текстовым представлением такого автомата. Этот последний пример выражается следующим регулярным выражением:
^[01]*1$
Которая соответствует любой строке, начинающейся с 0 или 1 , повторяя 0 или более раз, которая заканчивается на 1 . Другими словами, это регулярное выражение, чтобы соответствовать нечетным числам из их двоичного представления.
Являются ли все регулярные выражения регулярной грамматикой?
На самом деле это не так. Многие механизмы регулярных выражений улучшены и используют push-down automata , которые могут складываться и выгружать информацию по мере ее запуска. Эти автоматы определяют так называемые контекстно-свободные грамматики в иерархии Хомского. Наиболее типичным использованием в нерегулярном регулярном выражении является использование рекурсивного шаблона для сопоставления скобок.
Рекурсивным регулярным выражением, подобным приведенному ниже (что соответствует скобке), является примером такой реализации:
{((?>[^\(\)]+|(?R))*)}
(этот пример не работает с питона re двигателем, но с regex двигателя или с двигателем PCRE ).
Ресурсы
Для получения дополнительной информации о теории регулярных выражений вы можете обратиться к следующим курсам, предоставленным MIT:
- Автоматы, вычислимость и сложность
- Регулярные выражения и грамматики
- Указание языков с регулярными выражениями и контекстно-свободные грамматики
Когда вы пишете или отлаживаете сложное регулярное выражение, есть онлайн-инструменты, которые могут помочь визуализировать регулярные выражения как автоматы, такие как сайт debuggex .
Версии
PCRE
| Версия | Вышел |
|---|---|
| 2 | 2015-01-05 |
| 1 | 1997-06-01 |
Используется: PHP 4.2.0 (и выше), Delphi XE (и выше), Julia , Notepad ++
Perl
| Версия | Вышел |
|---|---|
| 1 | 1987-12-18 |
| 2 | 1988-06-05 |
| 3 | 1989-10-18 |
| 4 | 1991-03-21 |
| 5 | 1994-10-17 |
| 6 | 2009-07-28 |
.СЕТЬ
| Версия | Вышел |
|---|---|
| 1 | 2002-02-13 |
| 4 | 2010-04-12 |
Языки: C #
Джава
| Версия | Вышел |
|---|---|
| 4 | 2002-02-06 |
| 5 | 2004-10-04 |
| 7 | 2011-07-07 |
| SE8 | 2014-03-18 |
JavaScript
| Версия | Вышел |
|---|---|
| 1.2 | 1997-06-11 |
| 1.8.5 | 2010-07-27 |
питон
| Версия | Вышел |
|---|---|
| 1.4 | 1996-10-25 |
| 2,0 | 2000-10-16 |
| 3.0 | 2008-12-03 |
| 3.5.2 | 2016-06-07 |
Oniguruma
| Версия | Вышел |
|---|---|
| начальный | 2002-02-25 |
| 5.9.6 | 2014-12-12 |
| Onigmo | 2015-01-20 |
Увеличение
| Версия | Вышел |
|---|---|
| 0 | 1999-12-14 |
| 1.61.0 | 2016-05-13 |
POSIX
| Версия | Вышел |
|---|---|
| BRE | 1997-01-01 |
| ERE | 2008-01-01 |
Языки: Bash
Руководство персонажа
Обратите внимание, что некоторые элементы синтаксиса имеют различное поведение в зависимости от выражения.
| Синтаксис | Описание |
|---|---|
? | Сопоставьте предыдущий символ или подвыражение 0 или 1 раз. Также используется для групп без захвата и названных групп захвата. |
* | Сопоставьте предыдущий символ или подвыражение 0 или более раз. |
+ | Сопоставьте предыдущий символ или подвыражение 1 или более раз. |
{n} | Сопоставьте предыдущий символ или подвыражение ровно n раз. |
{min,} | Сопоставьте предыдущий символ или подвыражение мин или более раз. |
{,max} | Совпадение предшествующего символа или подвыражения макс или меньше. |
{min,max} | Сопоставьте предыдущий символ или подвыражение как минимум мин. Раз, но не более, чем max время. |
- | При включении в квадратных скобках указывает на то, to ; например, [3-6] соответствует символам 3, 4, 5 или 6. |
^ | Начало строки (или начало строки, если задана опция многострочного /m ), или отменяет список параметров (т. Е. В квадратных скобках [] ) |
$ | Конец строки (или конец строки, если указан параметр multiline /m ). |
( ... ) | Группирует подвыражения, захватывает совпадающее содержимое в специальных переменных ( \1 , \2 и т. Д.), Которые могут использоваться позже в одном и том же регулярном выражении, например (\w+)\s\1\s соответствует повторению слова |
(?<name> ... ) | Групповые подвыражения и захватывает их в именованной группе |
(?: ... ) | Групповые подвыражения без захвата |
. | Соответствует любому символу, кроме разрывов строк ( \n и обычно \r ). |
[ ... ] | Любой символ между этими скобками следует сопоставлять один раз. NB: ^ после открытой скобки отрицает этот эффект. - встречающийся внутри скобок позволяет задавать диапазон значений (если только это не первый или последний символ, и в этом случае он просто представляет собой обычную тире). |
\ | Убирает следующий символ. Также используется в мета-последовательностях - токены регулярного выражения со специальным значением. |
\$ | доллар (т. е. экранированный особый характер) |
\( | открытая скобка (т. е. экранированный специальный символ) |
\) | закрыть скобку (т. е. экранированный особый символ) |
\* | звездочка (т. е. экранированный особый символ) |
\. | точка (т. е. экранированный особый символ) |
\? | вопросительный знак (т. е. экранированный специальный символ) |
\[ | левая (открытая) квадратная скобка (т. е. экранированный специальный символ) |
\\ | обратная косая черта (т. е. экранированный особый символ) |
\] | правая (близкая) квадратная скобка (т.е. экранированный особый символ) |
\^ | карет (т. е. экранированный особый символ) |
\{ | левая (открытая) фигурная скобка / скобка (т.е. экранированный специальный символ) |
\| | труба (т. е. экранированный особый символ) |
\} | правая (близкая) фигурная скобка / скобка (т.е. экранированный особый символ) |
\+ | плюс (т. е. экранированный особый символ) |
\A | начало строки |
\Z | конец строки |
\z | абсолютная строка |
\b | слово (буквенно-цифровая последовательность) |
\1 , \2 и т. Д. | обратные ссылки на ранее согласованные подвыражения, сгруппированные по () , \1 означает первое совпадение, \2 означает второе совпадение и т. д. |
[\b] | backspace - когда \b находится внутри класса символов ( [] ) соответствует обратному пространству |
\B | negated \b - соответствует любой позиции между двумя словами, а также в любой позиции между двумя символами, отличными от слова |
\D | нецифровой |
\d | цифра |
\e | побег |
\f | форма подачи |
\n | line feed |
\r | возврат каретки |
\S | небелый-пространство |
\s | бело-пространство |
\t | табуляция |
\v | вертикальная вкладка |
\W | без слов |
\w | слово (например, буквенно-цифровой символ) |
{ ... } | набор символов |
| | или же; т.е. определяет предыдущие и предыдущие варианты. |