Regular Expressions Tutorial
Iniziare con le espressioni regolari
Ricerca…
Osservazioni
Per molti programmatori la regex è una sorta di spada magica che lanciano per risolvere qualsiasi tipo di situazione di analisi del testo. Ma questo strumento è nulla di magico, e anche se è grande in quello che fa, non è un linguaggio di programmazione piena funzionalità (cioè non è Turing-completo).
Cosa significa "espressione regolare"?
Le espressioni regolari esprimono un linguaggio definito da una grammatica regolare che può essere risolto da un automa finito non deterministico (NFA), in cui la corrispondenza è rappresentata dagli stati.
Una grammatica regolare è la grammatica più semplice espressa dalla Gerarchia di Chomsky .

Detto semplicemente, un linguaggio normale è visivamente espresso da ciò che un NFA può esprimere, ed ecco un semplice esempio di NFA:
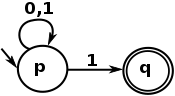
E il linguaggio delle espressioni regolari è una rappresentazione testuale di un tale automa. Quest'ultimo esempio è espresso dalla seguente espressione regolare:
^[01]*1$
Che corrisponde a qualsiasi stringa che inizia con 0 o 1 , ripetendo 0 o più volte, che termina con un 1 . In altre parole, è un'espressione regolare per abbinare numeri dispari dalla loro rappresentazione binaria.
Tutte le espressioni regolari sono in realtà una grammatica regolare ?
In realtà non lo sono. Molti motori regex sono migliorati e utilizzano gli automi push-down , che possono impilare e visualizzare informazioni mentre sono in esecuzione. Questi automi definiscono quelle che vengono chiamate grammatiche prive di contesto nella Gerarchia di Chomsky. L'uso più comune di quelli nella regex non regolare è l'uso di un pattern ricorsivo per la corrispondenza tra parentesi.
Una regex ricorsiva come la seguente (che corrisponde alla parentesi) è un esempio di tale implementazione:
{((?>[^\(\)]+|(?R))*)}
(questo esempio non funziona con re engine di Python, ma con il motore regex o con il motore PCRE ).
risorse
Per ulteriori informazioni sulla teoria alla base delle espressioni regolari, è possibile fare riferimento ai seguenti corsi messi a disposizione dal MIT:
- Automata, Computabilità e Complessità
- Espressioni regolari e grammatiche
- Specifica delle lingue con espressioni regolari e grammatiche context-free
Quando scrivi o esegui il debug di un'espressione regolare complessa, ci sono strumenti online che possono aiutare a visualizzare le espressioni regolari come automi, come il sito di debuggex .
Versioni
PCRE
| Versione | Rilasciato |
|---|---|
| 2 | 2015/01/05 |
| 1 | 1997/06/01 |
Utilizzato da: PHP 4.2.0 (e versioni successive), Delphi XE (e versioni successive), Julia , Notepad ++
Perl
| Versione | Rilasciato |
|---|---|
| 1 | 1987/12/18 |
| 2 | 1988/06/05 |
| 3 | 1989/10/18 |
| 4 | 1991/03/21 |
| 5 | 1994/10/17 |
| 6 | 2009-07-28 |
.NETTO
| Versione | Rilasciato |
|---|---|
| 1 | 2002/02/13 |
| 4 | 2010-04-12 |
Lingue: C #
Giava
| Versione | Rilasciato |
|---|---|
| 4 | 2002/02/06 |
| 5 | 2004-10-04 |
| 7 | 2011-07-07 |
| SE8 | 2014/03/18 |
JavaScript
| Versione | Rilasciato |
|---|---|
| 1.2 | 1997/06/11 |
| 1.8.5 | 2010-07-27 |
Pitone
| Versione | Rilasciato |
|---|---|
| 1.4 | 1996/10/25 |
| 2.0 | 2000/10/16 |
| 3.0 | 2008-12-03 |
| 3.5.2 | 2016/06/07 |
Oniguruma
| Versione | Rilasciato |
|---|---|
| Iniziale | 2002/02/25 |
| 5.9.6 | 2014/12/12 |
| Onigmo | 2015/01/20 |
Incremento
| Versione | Rilasciato |
|---|---|
| 0 | 1999/12/14 |
| 1.61.0 | 2016/05/13 |
POSIX
| Versione | Rilasciato |
|---|---|
| BRE | 1997-01-01 |
| ERE | 2008-01-01 |
Lingue: Bash
Guida ai caratteri
Si noti che alcuni elementi di sintassi hanno un comportamento diverso a seconda dell'espressione.
| Sintassi | Descrizione |
|---|---|
? | Abbina il carattere precedente o la sottoespressione 0 o 1 volte. Utilizzato anche per gruppi non di cattura e gruppi di cattura denominati. |
* | Abbina il carattere precedente o la sottoespressione 0 o più volte. |
+ | Abbina il carattere o la sottoespressione precedente 1 o più volte. |
{n} | Abbina il carattere o la sottoespressione precedente esattamente n volte. |
{min,} | Far corrispondere il carattere o espressione che precede min o più volte. |
{,max} | Abbina il carattere precedente o la sottoespressione al massimo o meno volte. |
{min,max} | Abbina il carattere o la sottoespressione precedente almeno min volte ma non più di max volte. |
- | Quando incluso tra parentesi quadre indica to ; ad es. [3-6] corrisponde ai caratteri 3, 4, 5 o 6. |
^ | Inizio della stringa (o inizio della riga se è specificata l'opzione multiline /m ) o annulla una lista di opzioni (cioè se tra parentesi quadre [] ) |
$ | Fine della stringa (o fine di una riga se è specificata l'opzione multiline /m ). |
( ... ) | Gruppi sottoespressioni, acquisisce contenuto corrispondente in variabili speciali ( \1 , \2 , ecc.) Che possono essere utilizzate successivamente all'interno della stessa espressione regolare, ad esempio (\w+)\s\1\s corrisponde alla ripetizione delle parole |
(?<name> ... ) | Raggruppa sottoespressioni e le acquisisce in un gruppo denominato |
(?: ... ) | Raggruppa sottoespressioni senza catturare |
. | Corrisponde a qualsiasi carattere tranne le interruzioni di riga ( \n e solitamente \r ). |
[ ... ] | Qualsiasi carattere tra queste parentesi dovrebbe essere abbinato una volta. NB: ^ seguendo la parentesi aperta si annulla questo effetto. - verifica all'interno delle parentesi consente di specificare un intervallo di valori (a meno che non sia il primo o l'ultimo carattere, nel qual caso rappresenta solo un trattino normale). |
\ | Sfugge al seguente carattere. Utilizzato anche in meta-sequenze - regex token con significato speciale. |
\$ | dollaro (cioè un carattere speciale sfuggito) |
\( | parentesi aperta (es. carattere speciale con escape) |
\) | parentesi chiusa (es. carattere speciale sfuggito) |
\* | asterisco (cioè un carattere speciale sfuggito) |
\. | punto (cioè un carattere speciale sfuggito) |
\? | punto interrogativo (cioè un carattere speciale sfuggito) |
\[ | parentesi quadra sinistra (aperta) (cioè un carattere speciale in fuga) |
\\ | backslash (cioè un carattere speciale di escape) |
\] | parentesi quadra destra (chiusa) (cioè un carattere speciale sfuggito) |
\^ | caret (cioè un carattere speciale sfuggito) |
\{ | parentesi graffa sinistra (aperta) / parentesi graffa (cioè un carattere speciale con escape) |
\| | pipe (cioè un carattere speciale di escape) |
\} | destra (vicino) parentesi graffa / parentesi graffa (cioè un carattere speciale sfuggito) |
\+ | più (cioè un carattere speciale in fuga) |
\A | inizio di una stringa |
\Z | fine di una stringa |
\z | assoluto di una stringa |
\b | confine di parola (sequenza alfanumerica) |
\1 , \2 , ecc. | riferimenti indietro a sottoespressioni precedentemente abbinate, raggruppate per () , \1 significa la prima corrispondenza, \2 significa seconda corrispondenza ecc. |
[\b] | backspace - quando \b è all'interno di una classe di caratteri ( [] ) corrisponde a backspace |
\B | negato \b - corrisponde a qualsiasi posizione tra i caratteri di due parole e in qualsiasi posizione tra due caratteri non di parole |
\D | non cifre |
\d | cifra |
\e | fuga |
\f | modulo di alimentazione |
\n | line feed |
\r | ritorno a capo |
\S | non white-space |
\s | white-space |
\t | linguetta |
\v | scheda verticale |
\W | non-parola |
\w | parola (cioè carattere alfanumerico) |
{ ... } | set di caratteri con nome |
| | o; cioè delinea le opzioni precedenti e precedenti. |