Regular Expressions Samouczek
Pierwsze kroki z wyrażeniami regularnymi
Szukaj…
Uwagi
Dla wielu programistów wyrażenie regularne jest rodzajem magicznego miecza, który rzucają w celu rozwiązania każdego rodzaju analizy tekstu. Ale to narzędzie ma nic magicznego, a mimo to jest świetne w tym co robi, nie jest to w pełni funkcjonalny język programowania (czyli nie jest kompletne Turinga).
Co oznacza „wyrażenie regularne”?
Wyrażenia regularne wyrażają język zdefiniowany przez gramatykę regularną, którą można rozwiązać za pomocą niedeterministycznego automatu skończonego (NFA), gdzie dopasowanie jest reprezentowane przez stany.
Gramatyka regularna to najprostsza gramatyka wyrażona przez hierarchię Chomsky'ego .

Mówiąc wprost, zwykły język jest wizualnie wyrażany przez to, co może wyrazić NFA, a oto bardzo prosty przykład NFA:
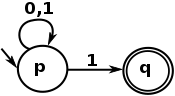
A język wyrażeń regularnych jest tekstową reprezentacją takiego automatu. Ten ostatni przykład jest wyrażony za pomocą następującego wyrażenia regularnego:
^[01]*1$
Który pasuje do dowolnego łańcucha rozpoczynającego się od 0 lub 1 , powtarzającego się 0 lub więcej razy, który kończy się na 1 . Innymi słowy, jest to wyrażenie regularne, aby dopasować liczby nieparzyste z ich reprezentacji binarnej.
Czy wszystkie wyrażenia regularne są w rzeczywistości zwykłą gramatyką?
W rzeczywistości tak nie jest. Wiele silników wyrażeń regularnych uległo poprawie i używa automatów przesuwających , które mogą się gromadzić i wyświetlać informacje w trakcie działania. Automaty te określają, co się nazywa gramatyk bezkontekstowych w hierarchii Chomsky'ego. Najbardziej typowym zastosowaniem tych w nieregularnym wyrażeniu regularnym jest użycie wzoru rekurencyjnego do dopasowywania nawiasów.
Przykładem takiej implementacji jest rekursywne wyrażenie regularne takie jak poniżej (które pasuje do nawiasów):
{((?>[^\(\)]+|(?R))*)}
(ten przykład nie działa z silnikiem re Pythona, ale z silnikiem regex lub z silnikiem PCRE ).
Zasoby
Więcej informacji na temat teorii wyrażeń regularnych można znaleźć w następujących kursach udostępnionych przez MIT:
- Automaty, obliczalność i złożoność
- Wyrażenia regularne i gramatyka
- Określanie języków z wyrażeniami regularnymi i gramatykami bezkontekstowymi
Podczas pisania lub debugowania złożonego wyrażenia regularnego istnieją narzędzia online, które mogą pomóc w wizualizacji wyrażeń regularnych jako automatów, na przykład witryna debuggex .
Wersje
PCRE
| Wersja | Wydany |
|---|---|
| 2) | 2015-01-05 |
| 1 | 01.06.1997 |
Używany przez: PHP 4.2.0 (i wyższe), Delphi XE (i wyższe), Julia , Notepad ++
Perl
| Wersja | Wydany |
|---|---|
| 1 | 1987-12-18 |
| 2) | 1988-06-05 |
| 3) | 1989-10-18 |
| 4 | 1991-03-21 |
| 5 | 1994-10-17 |
| 6 | 2009-07-28 |
.NETTO
| Wersja | Wydany |
|---|---|
| 1 | 2002-02-13 |
| 4 | 2010-04-12 |
Języki: C #
Jawa
| Wersja | Wydany |
|---|---|
| 4 | 2002-02-06 |
| 5 | 2004-10-04 |
| 7 | 2011-07-07 |
| SE8 | 18.03.2014 |
JavaScript
| Wersja | Wydany |
|---|---|
| 1.2 | 1997-06-11 |
| 1.8.5 | 2010-07-27 |
Pyton
| Wersja | Wydany |
|---|---|
| 1.4 | 1996-10-25 |
| 2.0 | 2000-10-16 |
| 3.0 | 2008-12-03 |
| 3.5.2 | 07.06.2016 |
Oniguruma
| Wersja | Wydany |
|---|---|
| Inicjał | 2002-02-25 |
| 5.9.6 | 2014-12-12 |
| Onigmo | 2015-01-20 |
Podnieść
| Wersja | Wydany |
|---|---|
| 0 | 1999-12-14 |
| 1.61.0 | 2016-05-13 |
POSIX
| Wersja | Wydany |
|---|---|
| BRE | 01.01.1997 |
| ERE | 01.01.2008 |
Języki: Bash
Przewodnik po postaciach
Zauważ, że niektóre elementy składniowe zachowują się inaczej w zależności od wyrażenia.
| Składnia | Opis |
|---|---|
? | Dopasuj poprzedni znak lub podwyrażenie 0 lub 1 razy. Używany również do grup przechwytywania i nazwanych grup przechwytywania. |
* | Dopasuj poprzedni znak lub podwyrażenie 0 lub więcej razy. |
+ | Dopasuj poprzedni znak lub podwyrażenie 1 lub więcej razy. |
{n} | Dopasuj poprzedni znak lub podwyrażenie dokładnie n razy. |
{min,} | Dopasuj poprzedni znak lub podwyrażenie min lub więcej razy. |
{,max} | Dopasuj poprzedni znak lub podwyrażenie maksymalnie lub mniej razy. |
{min,max} | Dopasuj poprzedni znak lub podwyrażenie co najmniej min razy, ale nie więcej niż max . Razy. |
- | Gdy zawarte w nawiasach kwadratowych wskazuje to ; np. [3-6] dopasowuje znaki 3, 4, 5 lub 6. |
^ | Początek ciągu (lub początek wiersza, jeśli podano opcję multiline /m ) lub neguje listę opcji (tzn. Jeśli w nawiasach kwadratowych [] ) |
$ | Koniec łańcucha (lub koniec linii, jeśli podano opcję multilinii /m ). |
( ... ) | Grupuje podwyrażenia, przechwytuje pasujące treści w specjalnych zmiennych ( \1 , \2 itd.), Których można użyć później w ramach tego samego wyrażenia regularnego, na przykład (\w+)\s\1\s dopasowuje powtarzanie słów |
(?<name> ... ) | Grupuje podwyrażenia i przechwytuje je w nazwanej grupie |
(?: ... ) | Grupuje podwyrażenia bez przechwytywania |
. | Odpowiada dowolnemu znakowi oprócz podziałów linii ( \n , i zwykle \r ). |
[ ... ] | Każdy znak między tymi nawiasami powinien być dopasowany jeden raz. Uwaga: ^ następujące po nawiasie otwartym neguje ten efekt. - występowanie w nawiasach pozwala określić zakres wartości (chyba że jest to pierwszy lub ostatni znak, w którym to przypadku reprezentuje zwykły myślnik). |
\ | Ucieka następującemu znakowi. Używany również w sekwencjach meta - tokenach regularnych o specjalnym znaczeniu. |
\$ | dolar (tj. specjalny znak ucieczki) |
\( | otwarty nawias (tzn. specjalny znak ucieczki) |
\) | ścisły nawias (tzn. znak specjalny, który uciekł) |
\* | gwiazdka (tj. specjalny znak ucieczki) |
\. | kropka (tzn. uciekający znak specjalny) |
\? | znak zapytania (tj. specjalny znak ucieczki) |
\[ | lewy (otwarty) nawias kwadratowy (tzn. specjalny znak ucieczki) |
\\ | ukośnik odwrotny (tzn. uciekł znak specjalny) |
\] | prawy (zamknięty) nawias kwadratowy (tzn. znak specjalny, który uciekł) |
\^ | daszek (tj. specjalny znak ucieczki) |
\{ | lewy (otwarty) nawias klamrowy / klamra (tzn. uciekł znak specjalny) |
\| | potok (tj. specjalny znak ucieczki) |
\} | prawy (zamknij) nawias klamrowy / klamra (tj. uciekający znak specjalny) |
\+ | plus (tj. specjalny znak ucieczki) |
\A | początek ciągu |
\Z | koniec łańcucha |
\z | absolut łańcucha |
\b | granica słowa (sekwencji alfanumerycznej) |
\1 , \2 itd. | odniesienia do poprzednio dopasowanych podwyrażeń, pogrupowane według () , \1 oznacza pierwsze dopasowanie, \2 oznacza drugie dopasowanie itp. |
[\b] | backspace - gdy \b znajduje się w klasie znaków ( [] ) dopasowuje backspace |
\B | negated \b - dopasowuje w dowolnej pozycji między znakami dwuliterowymi, a także w dowolnej pozycji między dwoma znakami niebędącymi wyrazami |
\D | niecyfrowe |
\d | cyfra |
\e | ucieczka |
\f | form feed |
\n | linia wiersza |
\r | powrót karetki |
\S | spoza białej przestrzeni |
\s | Biała przestrzeń |
\t | patka |
\v | zakładka pionowa |
\W | bez słów |
\w | słowo (tj. znak alfanumeryczny) |
{ ... } | nazwany zestaw znaków |
| | lub; tj. określa poprzednie i poprzednie opcje. |