Regular Expressions Handledning
Komma igång med Regular Expressions
Sök…
Anmärkningar
För många programmerare är regexet ett slags magiskt svärd som de kastar för att lösa alla typer av textupptäckningssituationer. Men det här verktyget är inget magiskt, och även om det är fantastiskt vad det gör, är det inte ett fullständigt programmeringsspråk ( dvs. det är inte Turing-komplett).
Vad betyder "regelbundet uttryck"?
Regelbundna uttryck uttrycker ett språk som definieras av en vanlig grammatik som kan lösas med en nondeterministic finite automat (NFA), där matchning representeras av staterna.
En vanlig grammatik är den mest enkla grammatiken som den uttrycks av Chomsky Hierarchy .

Enkelt sagt uttrycks ett vanligt språk visuellt av vad en NFA kan uttrycka, och här är ett mycket enkelt exempel på NFA:
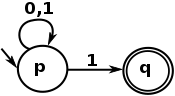
Och språket Regular Expression är en textlig representation av en sådan automat. Det sista exemplet uttrycks av följande regex:
^[01]*1$
Som matchar alla sträng som börjar med 0 eller 1 , upprepar 0 eller flera gånger, som slutar med en 1 . Med andra ord är det en regex som matchar udda siffror från deras binära representation.
Är alla regex faktiskt en vanlig grammatik?
Det är de faktiskt inte. Många regex-motorer har förbättrats och använder push-down automata , som kan stapla upp och visa information när den körs. Dessa automater definierar vad som kallas kontextfria grammatik i Chomskys hierarki. Den mest typiska användningen av dem i icke-regelbundet regex är användningen av ett rekursivt mönster för parentesmatchning.
Ett rekursivt regex som följande (som matchar parentes) är ett exempel på en sådan implementering:
{((?>[^\(\)]+|(?R))*)}
(detta exempel fungerar inte med Pythons re motor, utan med regex motorn eller med PCRE-motorn ).
Resurser
För mer information om teorin bakom Regular Expressions, kan du hänvisa till följande kurser tillgängliga av MIT:
- Automata, beräknbarhet och komplexitet
- Regelbundna uttryck och grammatik
- Ange språk med regelbundna uttryck och kontextfria grammatik
När du skriver eller felsöker ett komplext regex finns det onlineverktyg som kan hjälpa till att visualisera regexer som automatik, som felsökningswebbplatsen .
versioner
PCRE
| Version | Släppte |
|---|---|
| 2 | 2015/01/05 |
| 1 | 1997/06/01 |
Används av: PHP 4.2.0 (och högre), Delphi XE (och högre), Julia , Notepad ++
Perl
| Version | Släppte |
|---|---|
| 1 | 1987/12/18 |
| 2 | 1988/06/05 |
| 3 | 1989/10/18 |
| 4 | 1991/03/21 |
| 5 | 1994/10/17 |
| 6 | 2009-07-28 |
.NETTO
| Version | Släppte |
|---|---|
| 1 | 2002-02-13 |
| 4 | 2010-04-12 |
Språk: C #
Java
| Version | Släppte |
|---|---|
| 4 | 2002-02-06 |
| 5 | 2004-10-04 |
| 7 | 2011-07-07 |
| SE8 | 2014/03/18 |
JavaScript
| Version | Släppte |
|---|---|
| 1,2 | 1997/06/11 |
| 1.8.5 | 2010-07-27 |
Pytonorm
| Version | Släppte |
|---|---|
| 1,4 | 1996/10/25 |
| 2,0 | 2000/10/16 |
| 3,0 | 2008-12-03 |
| 3.5.2 | 2016/06/07 |
Oniguruma
| Version | Släppte |
|---|---|
| Första | 2002-02-25 |
| 5.9.6 | 2014/12/12 |
| Onigmo | 2015/01/20 |
Lyft
| Version | Släppte |
|---|---|
| 0 | 1999/12/14 |
| 1.61.0 | 2016/05/13 |
POSIX
| Version | Släppte |
|---|---|
| BRE | 1997-01-01 |
| ERE | 2008-01-01 |
Språk: Bash
Teckenguide
Observera att vissa syntaxelement har olika beteenden beroende på uttrycket.
| Syntax | Beskrivning |
|---|---|
? | Matcha föregående karaktär eller subexpression 0 eller 1 gånger. Används även för grupper som inte fångar och namngav fångstgrupper. |
* | Matcha föregående karaktär eller subexpression 0 eller flera gånger. |
+ | Matcha föregående karaktär eller subexpression en eller flera gånger. |
{n} | Matcha föregående karaktär eller subexpression exakt n gånger. |
{min,} | Matcha föregående karaktär eller subexpression min eller flera gånger. |
{,max} | Matcha föregående karaktär eller subexpression max eller färre gånger. |
{min,max} | Matcha föregående karaktär eller subexpression minst min gånger men högst max gånger. |
- | När det ingår mellan fyrkantiga parenteser indikerar to ; t.ex. [3-6] matchar tecken 3, 4, 5 eller 6. |
^ | Start av strängen (eller början av raden om multiline /m alternativet är specificerat), eller avvisar en lista med alternativ (dvs om inom fyrkantiga parenteser [] ) |
$ | Slut på strängen (eller slutet på en rad om alternativet multiline /m anges). |
( ... ) | Grupper subexpressions, fångar matchande innehåll i specialvariabler ( \1 , \2 , etc.) som kan användas senare inom samma regex, till exempel (\w+)\s\1\s matchar ordrepetition |
(?<name> ... ) | Grupper subexpressions och fångar dem i en namngiven grupp |
(?: ... ) | Grupper subexpressions utan att fånga |
. | Matchar alla tecken utom radbrytningar ( \n och vanligtvis \r ). |
[ ... ] | Alla tecken mellan dessa parenteser bör matchas en gång. OBS: ^ följer den öppna konsolen försvårar denna effekt. - inträffar inom parenteserna gör det möjligt att specificera ett intervall av värden (såvida det inte är det första eller sista tecknet, i vilket fall det bara representerar ett vanligt bindestreck). |
\ | Rymmer följande tecken. Används också i metasekvenser - regex-tokens med speciell betydelse. |
\$ | dollar (dvs en rymd specialtecken) |
\( | öppen parentes (dvs ett undkommet specialtecken) |
\) | nära parentes (dvs ett undkommet specialtecken) |
\* | asterisk (dvs en rymd specialtecken) |
\. | prick (dvs ett undkommet specialtecken) |
\? | frågetecken (dvs. ett undkommet specialtecken) |
\[ | vänster (öppen) fyrkantig konsol (dvs ett undkommet specialtecken) |
\\ | backslash (dvs ett undkommet specialtecken) |
\] | höger (nära) fyrkantig konsol (dvs ett undkommet specialtecken) |
\^ | caret (dvs en rymd specialtecken) |
\{ | vänster (öppen) lockig konsol / stag (dvs ett undkommet specialtecken) |
\| | rör (dvs ett undkommet specialtecken) |
\} | höger (nära) lockigt konsol / stag (dvs ett undkommet specialtecken) |
\+ | plus (dvs en rymd specialtecken) |
\A | början på en sträng |
\Z | slutet av en sträng |
\z | absolut av en sträng |
\b | ordgräns (alfanumerisk sekvens) |
\1 , \2 , etc. | bakreferenser till tidigare matchade subexpressions, grupperade efter () , \1 betyder den första matchen, \2 betyder andra match etc. |
[\b] | backspace - när \b är inne i en teckenklass ( [] ) matchar backspace |
\B | negated \b - matchar på vilken position som helst mellan två ordstecken och på vilken position som helst mellan två icke-ordstecken |
\D | icke-siffriga |
\d | siffra |
\e | fly |
\f | bilda foder |
\n | radmatning |
\r | vagnretur |
\S | non-white-space |
\s | white-space |
\t | flik |
\v | vertikal flik |
\W | icke-ord |
\w | ord (dvs alfanumeriskt tecken) |
{ ... } | namngivna teckenuppsättning |
| | eller; dvs avgränsar de föregående och föregående alternativen. |