Regular Expressions Tutorial
Empezando con Expresiones Regulares
Buscar..
Observaciones
Para muchos programadores, la expresión regular es una especie de espada mágica que lanzan para resolver cualquier tipo de situación de análisis de texto. Pero esta herramienta no es nada mágico, y aunque es muy bueno en lo que hace, no es un lenguaje de programación con todas las funciones (es decir, no es Turing completo).
¿Qué significa 'expresión regular'?
Las expresiones regulares expresan un lenguaje definido por una gramática regular que se puede resolver con un autómata finito no determinista (NFA), donde la coincidencia está representada por los estados.
Una gramática regular es la gramática más simple expresada por la Jerarquía de Chomsky .

En pocas palabras, un lenguaje regular se expresa visualmente por lo que puede expresar una NFA, y aquí hay un ejemplo muy simple de NFA:
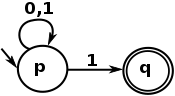
Y el lenguaje de Expresión Regular es una representación textual de tal autómata. Ese último ejemplo es expresado por el siguiente regex:
^[01]*1$
Que coincide con cualquier cadena que comience con 0 o 1 , repitiendo 0 o más veces, que termine con 1 . En otras palabras, es una expresión regular para hacer coincidir los números impares de su representación binaria.
¿Son todas las expresiones regulares una gramática regular ?
En realidad no lo son. Muchos motores de expresiones regulares han mejorado y están usando autómatas de empuje hacia abajo , que pueden acumularse y desplegar información a medida que se ejecuta. Esos autómatas definen lo que se llama gramáticas libres de contexto en la Jerarquía de Chomsky. El uso más típico de aquellos en expresiones regulares no regulares, es el uso de un patrón recursivo para la comparación de paréntesis.
Una expresión regular recursiva como la siguiente (que coincide con paréntesis) es un ejemplo de tal implementación:
{((?>[^\(\)]+|(?R))*)}
(este ejemplo no funciona con el motor de re de Python, sino con el motor de regex o con el motor de PCRE ).
Recursos
Para obtener más información sobre la teoría detrás de las expresiones regulares, puede consultar los siguientes cursos disponibles en el MIT:
- Autómatas, computabilidad y complejidad.
- Expresiones regulares y gramáticas
- Especificar idiomas con expresiones regulares y gramáticas libres de contexto
Cuando está escribiendo o depurando una expresión regular compleja, existen herramientas en línea que pueden ayudar a visualizar las expresiones regulares como autómatas, como el sitio de debuggex .
Versiones
PCRE
| Versión | Publicado |
|---|---|
| 2 | 2015-01-05 |
| 1 | 1997-06-01 |
Utilizado por: PHP 4.2.0 (y superior), Delphi XE (y superior), Julia , Notepad ++
Perl
| Versión | Publicado |
|---|---|
| 1 | 1987-12-18 |
| 2 | 1988-06-05 |
| 3 | 1989-10-18 |
| 4 | 1991-03-21 |
| 5 | 1994-10-17 |
| 6 | 2009-07-28 |
.RED
| Versión | Publicado |
|---|---|
| 1 | 2002-02-13 |
| 4 | 2010-04-12 |
Idiomas: C #
Java
| Versión | Publicado |
|---|---|
| 4 | 2002-02-06 |
| 5 | 2004-10-04 |
| 7 | 2011-07-07 |
| SE8 | 2014-03-18 |
JavaScript
| Versión | Publicado |
|---|---|
| 1.2 | 1997-06-11 |
| 1.8.5 | 2010-07-27 |
Pitón
| Versión | Publicado |
|---|---|
| 1.4 | 1996-10-25 |
| 2.0 | 2000-10-16 |
| 3.0 | 2008-12-03 |
| 3.5.2 | 2016-06-07 |
Oniguruma
| Versión | Publicado |
|---|---|
| Inicial | 2002-02-25 |
| 5.9.6 | 2014-12-12 |
| Onigmo | 2015-01-20 |
Aumentar
| Versión | Publicado |
|---|---|
| 0 | 1999-12-14 |
| 1.61.0 | 2016-05-13 |
POSIX
| Versión | Publicado |
|---|---|
| BRE | 1997-01-01 |
| ANTES DE | 2008-01-01 |
Idiomas: Bash
Guia de personajes
Tenga en cuenta que algunos elementos de sintaxis tienen un comportamiento diferente según la expresión.
| Sintaxis | Descripción |
|---|---|
? | Haga coincidir el carácter o subexpresión anterior 0 o 1 veces. También se usa para grupos que no capturan, y grupos de captura nombrados. |
* | Coincidir con el carácter o subexpresión anterior 0 o más veces. |
+ | Coincidir con el carácter o subexpresión anterior 1 o más veces. |
{n} | Haga coincidir el carácter o subexpresión precedente exactamente n veces. |
{min,} | Coincidir con el carácter anterior o subexpresión mínimo o más veces. |
{,max} | Coincidir con el carácter anterior o subexpresión máximo o menos veces. |
{min,max} | Haga coincidir el carácter o subexpresión precedente al menos un mínimo de veces, pero no más de un max veces. |
- | Cuando se incluye entre corchetes indica to ; por ejemplo, [3-6] coincide con los caracteres 3, 4, 5 o 6. |
^ | Inicio de cadena (o inicio de línea si se especifica la opción multilínea /m ), o niega una lista de opciones (es decir, si se encuentra entre corchetes [] ) |
$ | Fin de cadena (o final de una línea si se especifica la opción multilínea /m ). |
( ... ) | Subexpresiones de grupos, captura contenido coincidente en variables especiales ( \1 , \2 , etc.) que se pueden usar más adelante dentro de la misma expresión regular, por ejemplo (\w+)\s\1\s coincide con la repetición de palabras |
(?<name> ... ) | Subexpresiones de grupos, y las captura en un grupo nombrado |
(?: ... ) | Subexpresiones de grupos sin captura. |
. | Coincide con cualquier carácter, excepto los saltos de línea ( \n , y normalmente \r ). |
[ ... ] | Cualquier carácter entre estos paréntesis debe coincidir una vez. NB: ^ siguiendo el corchete abierto niega este efecto. - aparecer dentro de los corchetes, se puede especificar un rango de valores (a menos que sea el primer o último carácter, en cuyo caso solo representa un guión normal). |
\ | Escapa del siguiente personaje. También se usa en secuencias meta - toques de expresión regular con significado especial. |
\$ | dólar (es decir, un personaje especial escapado) |
\( | paréntesis abiertos (es decir, un carácter especial escapado) |
\) | paréntesis de cierre (es decir, un carácter especial escapado) |
\* | asterisco (es decir, un carácter especial escapado) |
\. | punto (es decir, un carácter especial escapado) |
\? | signo de interrogación (es decir, un carácter especial escapado) |
\[ | corchete izquierdo (abierto) (es decir, un carácter especial escapado) |
\\ | barra invertida (es decir, un carácter especial escapado) |
\] | corchete derecho (cerrado) (es decir, un carácter especial escapado) |
\^ | caret (es decir, un personaje especial escapado) |
\{ | corchete / soporte izquierdo (abierto) (es decir, un carácter especial escapado) |
\| | pipa (es decir, un personaje especial escapado) |
\} | corchete / soporte derecho (cerrado) (es decir, un carácter especial escapado) |
\+ | más (es decir, un personaje especial escapado) |
\A | comienzo de una cuerda |
\Z | final de una cadena |
\z | absoluto de una cuerda |
\b | palabra (secuencia alfanumérica) límite |
\1 , \2 , etc. | las referencias anteriores a subexpresiones coincidentes anteriormente, agrupadas por () , \1 significa la primera coincidencia, \2 significa la segunda coincidencia, etc. |
[\b] | retroceso: cuando \b está dentro de una clase de caracteres ( [] ) coincide con retroceso |
\B | negated \b - coincide en cualquier posición entre caracteres de dos palabras así como en cualquier posición entre dos caracteres que no sean palabras |
\D | sin dígitos |
\d | dígito |
\e | escapar |
\f | form feed |
\n | linea de alimentación |
\r | retorno de carro |
\S | espacio no blanco |
\s | espacio en blanco |
\t | lengüeta |
\v | pestaña vertical |
\W | no palabra |
\w | palabra (es decir, carácter alfanumérico) |
{ ... } | conjunto de caracteres con nombre |
| | o; Es decir, delinea las opciones anteriores y anteriores. |