Regular Expressions チュートリアル
正規表現の使い方
サーチ…
備考
多くのプログラマにとって、 正規表現は、あらゆる種類のテキスト解析状況を解決するために投げる魔法の剣のようなものです。しかし、このツールは魔法のようなものではありません。たとえそれが優れていても、フル機能のプログラミング言語ではありません ( つまり 、Turing-completeではありません )。
「正規表現」とはどういう意味ですか?
正規表現は 、 非決定的有限オートマトン (NFA)によって解決できる規則的な文法によって定義された言語を表現します。ここで、一致は状態によって表されます。
通常の文法は、 チョムスキー階層によって表現される最も単純な文法である。

簡単に言えば、通常の言語はNFAが表現できるものによって視覚的に表現されています。ここにはNFAの非常に単純な例があります:
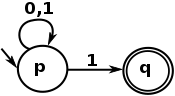
また、 正規表現言語は、そのようなオートマトンのテキスト表現です。最後の例は次の正規表現で表現されます:
^[01]*1$
0または1で始まる任意の文字列にマッチし、 0回以上繰り返され、 1で終わる文字列。言い換えれば、バイナリ表現からの奇数と一致するのは正規表現です。
すべての正規表現は実際には正規の文法ですか?
実際にはそうではありません。多くの正規表現エンジンが改良され、 プッシュダウンオートマトンを使用しており、積み重ねることができ、実行中の情報をポップダウンすることができます。これらのオートマトンは、チョムスキーの階層構造の文脈自由文法を定義します。非正規正規表現でのそれらの最も典型的な使用は、かっこのマッチングのための再帰的パターンの使用です。
このような実装の例は、次のような(括弧に一致する)再帰的な正規表現です。
{((?>[^\(\)]+|(?R))*)}
(この例は、Pythonのreエンジンではなくregexエンジンで 、またはPCREエンジンでは機能しません)。
リソース
正規表現の背後にある理論の詳細については、MITが提供する以下のコースを参照することができます。
複雑な正規表現を書くときやデバッグするときには、 debuggexサイトのように、正規表現をオートマトンとして視覚化するためのオンラインツールがあります。
バージョン
PCRE
| バージョン | 解放された |
|---|---|
| 2 | 2015-01-05 |
| 1 | 1997-06-01 |
使用者: PHP 4.2.0(以上)、 Delphi XE(以上)、 Julia 、 Notepad ++
Perl
| バージョン | 解放された |
|---|---|
| 1 | 1987年12月18日 |
| 2 | 1988-06-05 |
| 3 | 1989-10-18 |
| 4 | 1991年3月21日 |
| 5 | 1994-10-17 |
| 6 | 2009年7月28日 |
。ネット
| バージョン | 解放された |
|---|---|
| 1 | 2002-02-13 |
| 4 | 2010-04-12 |
言語: C#
Java
| バージョン | 解放された |
|---|---|
| 4 | 2002-02-06 |
| 5 | 2004年10月4日 |
| 7 | 2011年7月7日 |
| SE8 | 2014-03-18 |
JavaScript
| バージョン | 解放された |
|---|---|
| 1.2 | 1997年06月11日 |
| 1.8.5 | 2010-07-27 |
Python
| バージョン | 解放された |
|---|---|
| 1.4 | 1996年10月25日 |
| 2.0 | 2000-10-16 |
| 3.0 | 2008-12-03 |
| 3.5.2 | 2016年6月7日 |
オニグルマ
| バージョン | 解放された |
|---|---|
| 初期 | 2002-02-25 |
| 5.9.6 | 2014-12-12 |
| Onigmo | 2015-01-20 |
ブースト
| バージョン | 解放された |
|---|---|
| 0 | 1999-12-14 |
| 1.61.0 | 2016年5月13日 |
POSIX
| バージョン | 解放された |
|---|---|
| BRE | 1997-01-01 |
| ERE | 2008-01-01 |
言語: Bash
キャラクターガイド
いくつかの構文要素は、式によって異なる動作をすることに注意してください。
| 構文 | 説明 |
|---|---|
? | 直前の文字または部分式を0回または1回マッチさせる。また、非キャプチャグループと名前付きキャプチャグループにも使用されます。 |
* | 前の文字または部分式を0回以上マッチさせる。 |
+ | 直前の文字または部分式を1回以上マッチさせる。 |
{n} | 前の文字または部分式を正確にn回マッチさせる。 |
{min,} | 直前の文字または部分式を分以上一致させます。 |
{,max} | 直前の文字または部分式を最大またはそれ以下で一致させます。 |
{min,max} | 直前の文字または部分式を少なくともmin回以上max回以下で一致させます。 |
- | 大括弧で囲まれto場合はto示します。例えば、[3-6]は、文字3,4,5、または6に一致します。 |
^ | 文字列の開始(または複数行/mオプションが指定されている場合は行の先頭)、またはオプションのリストを無効にします(つまり、角括弧[]内にある場合) |
$ | 文字列の終わり(または、複数行/mオプションが指定されている場合は行末)。 |
( ... ) | (\w+)\s\1\sように、同じ正規表現内で後で使用できる特殊変数( \1 、 \2など)で一致するコンテンツをキャプチャします。 |
(?<name> ... ) | サブエクスプレッションをグループ化し、名前付きグループでキャプチャします |
(?: ... ) | キャプチャしないでサブコマンドをグループ化する |
. | 改行( \n 、通常\r )以外のすべての文字と一致します。 |
[ ... ] | これらの括弧の間の文字は一度一致させる必要があります。 NB: ^オープンブラケット以下は、この効果を否定します。 -角括弧の中で発生すると、範囲の値を指定することができます(最初の文字または最後の文字以外の場合、通常のダッシュを表します)。 |
\ | 次の文字をエスケープします。メタシーケンスでも使われます。特別な意味を持つ正規表現トークンです。 |
\$ | ドル(すなわちエスケープされた特殊文字) |
\( | オープンカッコ(すなわち、エスケープされた特殊文字) |
\) | 閉じ括弧(つまり、エスケープされた特殊文字) |
\* | アスタリスク(エスケープされた特殊文字) |
\. | ドット(エスケープされた特殊文字) |
\? | 疑問符(エスケープされた特殊文字) |
\[ | 角括弧を左(開いている)(つまり、エスケープされた特殊文字) |
\\ | バックスラッシュ(エスケープされた特殊文字) |
\] | 右(閉じる)角括弧(エスケープされた特殊文字) |
\^ | キャレット(エスケープされた特殊文字) |
\{ | 左(開いた)中かっこ/中括弧(エスケープされた特殊文字) |
\| | パイプ(エスケープされた特殊文字) |
\} | 右(閉じる)中かっこ/中括弧(エスケープされた特殊文字) |
\+ | プラス(エスケープされた特殊文字) |
\A | 文字列の開始 |
\Z | 文字列の終わり |
\z | 文字列の絶対値 |
\b | 単語(英数字列)の境界 |
\1 、 \2など | 以前に一致した部分式への逆参照は、 ()でグループ化され、 \1は最初の一致を意味し、 \2は2番目の一致などを意味します。 |
[\b] | backspace - \bが文字クラス( [] )の中にあるとき、バックスペースにマッチする |
\B | 否定された\b - 2単語の文字の間の任意の位置と、2つの非単語の文字の間の任意の位置に一致する |
\D | 非桁 |
\d | 桁 |
\e | エスケープ |
\f | フォームフィード |
\n | 改行 |
\r | キャリッジリターン |
\S | 非空白 |
\s | 空白 |
\t | タブ |
\v | 垂直タブ |
\W | 非単語 |
\w | 単語(すなわち英数字) |
{ ... } | 名前付き文字セット |
| | または;すなわち、先行オプションと先行オプションの輪郭を描く。 |