Regular Expressions Tutoriel
Démarrer avec les expressions régulières
Recherche…
Remarques
Pour beaucoup de programmeurs, le regex est une sorte d'épée magique qu'ils lancent pour résoudre tout type d'analyse de texte. Mais cet outil n’a rien de magique, et même si c’est très bien, ce n’est pas un langage de programmation complet ( c’est- à- dire qu’il n’est pas complet).
Que signifie l'expression régulière?
Les expressions régulières expriment un langage défini par une grammaire régulière pouvant être résolue par un automate fini non déterministe (NFA), où la correspondance est représentée par les états.
Une grammaire régulière est la grammaire la plus simple exprimée par la hiérarchie de Chomsky .

En termes simples, un langage régulier est exprimé visuellement par ce qu'une NFA peut exprimer, et voici un exemple très simple de NFA:
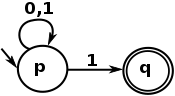
Et le langage Regular Expression est une représentation textuelle d'un tel automate. Ce dernier exemple est exprimé par l'expression rationnelle suivante:
^[01]*1$
Qui correspond à une chaîne commençant par 0 ou 1 , en répétant 0 fois ou plus, qui se termine par 1 . En d'autres termes, c'est une expression rationnelle qui permet de faire correspondre les nombres impairs de leur représentation binaire.
Toutes les regex sont-elles réellement une grammaire régulière ?
En fait, ils ne le sont pas. De nombreux moteurs regex ont été améliorés et utilisent des automates déroulants , qui peuvent s’accumuler et afficher des informations au fur et à mesure de leur exécution. Ces automates définissent ce qu'on appelle des grammaires sans contexte dans la hiérarchie de Chomsky. L'utilisation la plus courante de celles dans les regex non régulières est l'utilisation d'un modèle récursif pour la correspondance entre parenthèses.
Une expression rationnelle récursive comme celle qui suit (qui correspond à une parenthèse) est un exemple d'une telle implémentation:
{((?>[^\(\)]+|(?R))*)}
(cet exemple ne fonctionne pas avec le moteur re de python, mais avec le moteur regex ou avec le moteur PCRE ).
Ressources
Pour plus d'informations sur la théorie derrière les expressions régulières, vous pouvez vous référer aux cours suivants mis à disposition par le MIT:
- Automates, calculabilité et complexité
- Expressions régulières et Grammars
- Spécification de langues avec des expressions régulières et des grammaires sans contexte
Lorsque vous écrivez ou déboguez une expression rationnelle complexe, il existe des outils en ligne qui peuvent aider à visualiser les expressions rationnelles en tant qu'automates, comme le site debuggex .
Versions
PCRE
| Version | Libéré |
|---|---|
| 2 | 2015-01-05 |
| 1 | 1997-06-01 |
Utilisé par: PHP 4.2.0 (et supérieur), Delphi XE (et supérieur), Julia , Notepad ++
Perl
| Version | Libéré |
|---|---|
| 1 | 1987-12-18 |
| 2 | 1988-06-05 |
| 3 | 1989-10-18 |
| 4 | 1991-03-21 |
| 5 | 1994-10-17 |
| 6 | 2009-07-28 |
.NET
| Version | Libéré |
|---|---|
| 1 | 2002-02-13 |
| 4 | 2010-04-12 |
Langues: C #
Java
| Version | Libéré |
|---|---|
| 4 | 2002-02-06 |
| 5 | 2004-10-04 |
| 7 | 2011-07-07 |
| SE8 | 2014-03-18 |
JavaScript
| Version | Libéré |
|---|---|
| 1.2 | 1997-06-11 |
| 1.8.5 | 2010-07-27 |
Python
| Version | Libéré |
|---|---|
| 1.4 | 1996-10-25 |
| 2.0 | 2000-10-16 |
| 3.0 | 2008-12-03 |
| 3.5.2 | 2016-06-07 |
Oniguruma
| Version | Libéré |
|---|---|
| Initiale | 2002-02-25 |
| 5.9.6 | 2014-12-12 |
| Onigmo | 2015-01-20 |
Renforcer
| Version | Libéré |
|---|---|
| 0 | 1999-12-14 |
| 1,61.0 | 2016-05-13 |
POSIX
| Version | Libéré |
|---|---|
| BRE | 1997-01-01 |
| AVANT | 2008-01-01 |
Langues: Bash
Guide du personnage
Notez que certains éléments de syntaxe ont un comportement différent selon l'expression.
| Syntaxe | La description |
|---|---|
? | Faites correspondre le caractère ou la sous-expression précédent 0 ou 1 fois. Également utilisé pour les groupes non capturés et les groupes de capture nommés. |
* | Faites correspondre le caractère précédent ou la sous-expression 0 ou plusieurs fois. |
+ | Faites correspondre le caractère ou la sous-expression précédent une ou plusieurs fois. |
{n} | Faites correspondre le caractère ou la sous-expression précédent exactement n fois. |
{min,} | Faites correspondre le caractère précédent ou la sous-expression au moins plusieurs fois. |
{,max} | Faites correspondre le caractère précédent ou la sous-expression max ou moins. |
{min,max} | Faites correspondre le caractère ou la sous-expression précédent avec les temps minimum , mais pas plus que les durées max . |
- | Lorsque inclus entre crochets indique to ; Par exemple, [3-6] correspond aux caractères 3, 4, 5 ou 6. |
^ | Début de chaîne (ou début de ligne si l'option multiline /m est spécifiée) ou annule une liste d'options (par exemple, si elle est entre crochets [] ) |
$ | Fin de chaîne (ou fin d'une ligne si l'option multiligne /m est spécifiée). |
( ... ) | Groupes sous-expressions, capture le contenu correspondant dans des variables spéciales ( \1 , \2 , etc.) pouvant être utilisées ultérieurement dans la même expression régulière, par exemple (\w+)\s\1\s correspond à la répétition des mots |
(?<name> ... ) | Regroupe les sous-expressions et les capture dans un groupe nommé |
(?: ... ) | Regrouper les sous-expressions sans capturer |
. | Correspond à n'importe quel caractère sauf les sauts de ligne ( \n et généralement \r ). |
[ ... ] | Tout caractère entre ces parenthèses devrait être associé une fois. NB: ^ suivre le crochet ouvert annule cet effet. - dans les parenthèses, une plage de valeurs peut être spécifiée (à moins que ce soit le premier ou le dernier caractère, auquel cas il ne représente qu'un tiret régulier). |
\ | Échappe au caractère suivant. Également utilisé dans les méta-séquences - les jetons regex ayant une signification particulière. |
\$ | dollar (c.-à-d. un caractère spécial échappé) |
\( | parenthèse ouverte (c'est-à-dire un caractère spécial échappé) |
\) | parenthèse proche (c.-à-d. un caractère spécial échappé) |
\* | astérisque (c'est-à-dire un caractère spécial échappé) |
\. | dot (c'est-à-dire un caractère spécial échappé) |
\? | point d'interrogation (c'est-à-dire un caractère spécial échappé) |
\[ | crochet gauche (ouvert) (c'est-à-dire un caractère spécial échappé) |
\\ | barre oblique inverse (c'est-à-dire un caractère spécial échappé) |
\] | crochet droit (proche) (c'est-à-dire un caractère spécial échappé) |
\^ | caret (c'est-à-dire un caractère spécial échappé) |
\{ | accolade / accolade gauche (ouverte) (c'est-à-dire un caractère spécial échappé) |
\| | pipe (c'est-à-dire un caractère spécial échappé) |
\} | accolades / accolades (c'est-à-dire un caractère spécial échappé) |
\+ | plus (c'est-à-dire un caractère spécial échappé) |
\A | début d'une chaîne |
\Z | fin d'une chaîne |
\z | absolu d'une chaîne |
\b | limite de mot (séquence alphanumérique) |
\1 , \2 , etc. | back-references à des sous-expressions précédentes, regroupées par () , \1 signifie la première correspondance, \2 signifie deuxième correspondance, etc. |
[\b] | backspace - quand \b trouve dans une classe de caractères ( [] ) correspond à un retour arrière |
\B | négation \b - correspond à n'importe quelle position entre caractères à deux mots et à n'importe quelle position entre deux caractères non-mots |
\D | non-chiffre |
\d | chiffre |
\e | échapper |
\f | aliment de forme |
\n | saut de ligne |
\r | retour de chariot |
\S | espace non blanc |
\s | espace blanc |
\t | languette |
\v | onglet vertical |
\W | non-mot |
\w | mot (caractère alphanumérique) |
{ ... } | jeu de caractères nommé |
| | ou; c'est-à-dire délimite les options précédentes et précédentes. |