Regular Expressions Zelfstudie
Aan de slag met reguliere expressies
Zoeken…
Opmerkingen
Voor veel programmeurs is de regex een soort magisch zwaard dat ze gooien om elke vorm van tekstparsing op te lossen. Maar deze tool is niets magisch, en hoewel het geweldig is in wat het doet, is het geen volledige programmeertaal ( dwz het is niet Turing-compleet).
Wat betekent 'reguliere expressie'?
Reguliere expressies drukken een taal uit die wordt gedefinieerd door een reguliere grammatica die kan worden opgelost door een niet-deterministische eindige automaat (NFA), waarbij matching wordt voorgesteld door de staten.
Een normale grammatica is de meest eenvoudige grammatica zoals uitgedrukt door de Chomsky-hiërarchie .

Eenvoudig gezegd, een gewone taal wordt visueel uitgedrukt door wat een NFA kan uitdrukken, en hier is een heel eenvoudig voorbeeld van NFA:
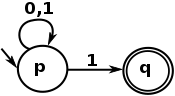
En de taal van de reguliere expressie is een tekstuele weergave van een dergelijke automaat. Dat laatste voorbeeld wordt uitgedrukt door de volgende regex:
^[01]*1$
Die overeenkomt met elke tekenreeks die begint met 0 of 1 , die 0 of meer keren wordt herhaald en eindigt met een 1 . Met andere woorden, het is een regex om oneven nummers van hun binaire weergave te matchen.
Zijn alle regex eigenlijk een normale grammatica?
Eigenlijk zijn ze dat niet. Veel regex-engines zijn verbeterd en gebruiken push-down-automaten die informatie kunnen stapelen en naar beneden kunnen laten springen terwijl deze wordt uitgevoerd. Die automaten definiëren wat contextvrije grammatica's worden genoemd in Chomsky's Hiërarchie. Het meest typische gebruik van die in niet-reguliere regex , is het gebruik van een recursief patroon voor het vergelijken van haakjes.
Een recursieve regex zoals de volgende (die overeenkomt met haakjes) is een voorbeeld van een dergelijke implementatie:
{((?>[^\(\)]+|(?R))*)}
(dit voorbeeld werkt niet met de re engine van python, maar met de regex engine of met de PCRE-engine ).
Middelen
Voor meer informatie over de theorie achter Reguliere Expressies, kunt u verwijzen naar de volgende cursussen beschikbaar gesteld door MIT:
- Automaat, berekenbaarheid en complexiteit
- Reguliere uitdrukkingen en grammatica's
- Talen opgeven met reguliere expressies en contextvrije grammatica's
Wanneer u een complexe regex schrijft of debugt, zijn er online tools die regexes kunnen helpen visualiseren als automaten, zoals de debuggex-site .
versies
PCRE
| Versie | Vrijgelaten |
|---|---|
| 2 | 2015/01/05 |
| 1 | 1997/06/01 |
Gebruikt door: PHP 4.2.0 (en hoger), Delphi XE (en hoger), Julia , Notepad ++
Perl
| Versie | Vrijgelaten |
|---|---|
| 1 | 1987/12/18 |
| 2 | 1988/06/05 |
| 3 | 1989/10/18 |
| 4 | 1991/03/21 |
| 5 | 1994/10/17 |
| 6 | 2009-07-28 |
.NETTO
| Versie | Vrijgelaten |
|---|---|
| 1 | 2002/02/13 |
| 4 | 2010-04-12 |
Talen: C #
Java
| Versie | Vrijgelaten |
|---|---|
| 4 | 2002/02/06 |
| 5 | 2004-10-04 |
| 7 | 2011-07-07 |
| SE8 | 2014/03/18 |
JavaScript
| Versie | Vrijgelaten |
|---|---|
| 1.2 | 1997/06/11 |
| 1.8.5 | 2010-07-27 |
Python
| Versie | Vrijgelaten |
|---|---|
| 1.4 | 1996/10/25 |
| 2.0 | 2000/10/16 |
| 3.0 | 2008-12-03 |
| 3.5.2 | 2016/06/07 |
Oniguruma
| Versie | Vrijgelaten |
|---|---|
| Eerste | 2002/02/25 |
| 5.9.6 | 2014/12/12 |
| Onigmo | 2015/01/20 |
boost
| Versie | Vrijgelaten |
|---|---|
| 0 | 1999/12/14 |
| 1.61.0 | 2016/05/13 |
POSIX
| Versie | Vrijgelaten |
|---|---|
| BRE | 1997-01-01 |
| ERE | 2008-01-01 |
Talen: Bash
Karaktergids
Merk op dat sommige syntaxiselementen verschillend gedrag vertonen, afhankelijk van de uitdrukking.
| Syntaxis | Beschrijving |
|---|---|
? | Overeenkomen met het voorgaande teken of subexpressie 0 of 1 keer. Wordt ook gebruikt voor niet-vastleggende groepen en benoemde vastleggroepen. |
* | Overeenkomen met het vorige teken of subexpressie 0 of meer keer. |
+ | Overeenkomen met het voorgaande teken of subexpressie 1 of meer keer. |
{n} | Overeenkomen met het vorige teken of subexpressie precies n keer. |
{min,} | Overeenkomen met het vorige teken of subexpressie min of meer keer. |
{,max} | Pas maximaal of minder overeen met het voorgaande teken of de subuitdrukking. |
{min,max} | Overeenkomen met het voorgaande teken of subexpressie ten minste min keer, maar niet meer dan max keer. |
- | Indien opgenomen tussen vierkante haakjes geeft to ; bijv. [3-6] komt overeen met tekens 3, 4, 5 of 6. |
^ | Begin van de reeks (of begin van de regel als de optie multiline /m is opgegeven), of een lijst met opties teniet doet (dwz als tussen vierkante haken [] ) |
$ | Einde string (of einde van een lijn als de optie multiline /m is opgegeven). |
( ... ) | Groeps-subexpressies, legt overeenkomende inhoud vast in speciale variabelen ( \1 , \2 , enz.) Die later binnen dezelfde regex kunnen worden gebruikt, bijvoorbeeld (\w+)\s\1\s overeen met woordherhaling |
(?<name> ... ) | Subexpressies van groepen en legt deze vast in een benoemde groep |
(?: ... ) | Subexpressies van groepen zonder vast te leggen |
. | Komt overeen met elk teken behalve regelafbrekingen ( \n , en meestal \r ). |
[ ... ] | Elk karakter tussen deze haakjes moet eenmaal worden gematcht. NB: ^ volgen van de open haakje doet dit effect teniet. - tussen de haakjes kan een bereik van waarden worden opgegeven (tenzij dit het eerste of laatste teken is, in welk geval het gewoon een normaal streepje vertegenwoordigt). |
\ | Ontsnapt aan het volgende karakter. Ook gebruikt in meta-reeksen - regex-tokens met speciale betekenis. |
\$ | dollar (dwz een ontsnapt speciaal teken) |
\( | open haakjes (dwz een ontsnapt speciaal teken) |
\) | haakje sluiten (dwz een ontsnapt speciaal teken) |
\* | asterisk (dwz een ontsnapt speciaal teken) |
\. | punt (dwz een ontsnapt speciaal teken) |
\? | vraagteken (dwz een ontsnapt speciaal teken) |
\[ | linker (open) vierkante haakje (dwz een ontsnapt speciaal teken) |
\\ | backslash (dwz een ontsnapt speciaal teken) |
\] | rechter (dichte) vierkante haak (dwz een ontsnapt speciaal teken) |
\^ | caret (dwz een ontsnapt speciaal karakter) |
\{ | linker (open) accolade / accolade (dwz een ontsnapt speciaal teken) |
\| | pijp (dwz een ontsnapt speciaal karakter) |
\} | rechter (dichte) accolade / accolade (dwz een ontsnapt speciaal teken) |
\+ | plus (dwz een ontsnapt speciaal teken) |
\A | begin van een string |
\Z | einde van een string |
\z | absoluut van een string |
\b | woord (alfanumerieke volgorde) grens |
\1 , \2 , etc. | terugverwijzingen naar eerder overeenkomende subexpressies, gegroepeerd op () , \1 betekent de eerste overeenkomst, \2 betekent tweede overeenkomst enz. |
[\b] | backspace - wanneer \b zich in een tekenklasse ( [] ) bevindt, komt deze overeen met backspace |
\B | negated \b - komt overeen met elke positie tussen tekens met twee woorden en op elke positie tussen twee tekens zonder woorden |
\D | non-cijferige |
\d | cijfer |
\e | ontsnappen |
\f | formulier feed |
\n | lijn feed |
\r | vervoer terug |
\S | non-white-space |
\s | witte ruimte |
\t | tab |
\v | verticale tab |
\W | non-woord |
\w | woord (dwz alfanumeriek teken) |
{ ... } | benoemde tekenset |
| | of; dat wil zeggen, de voorgaande en voorgaande opties worden afgebakend. |